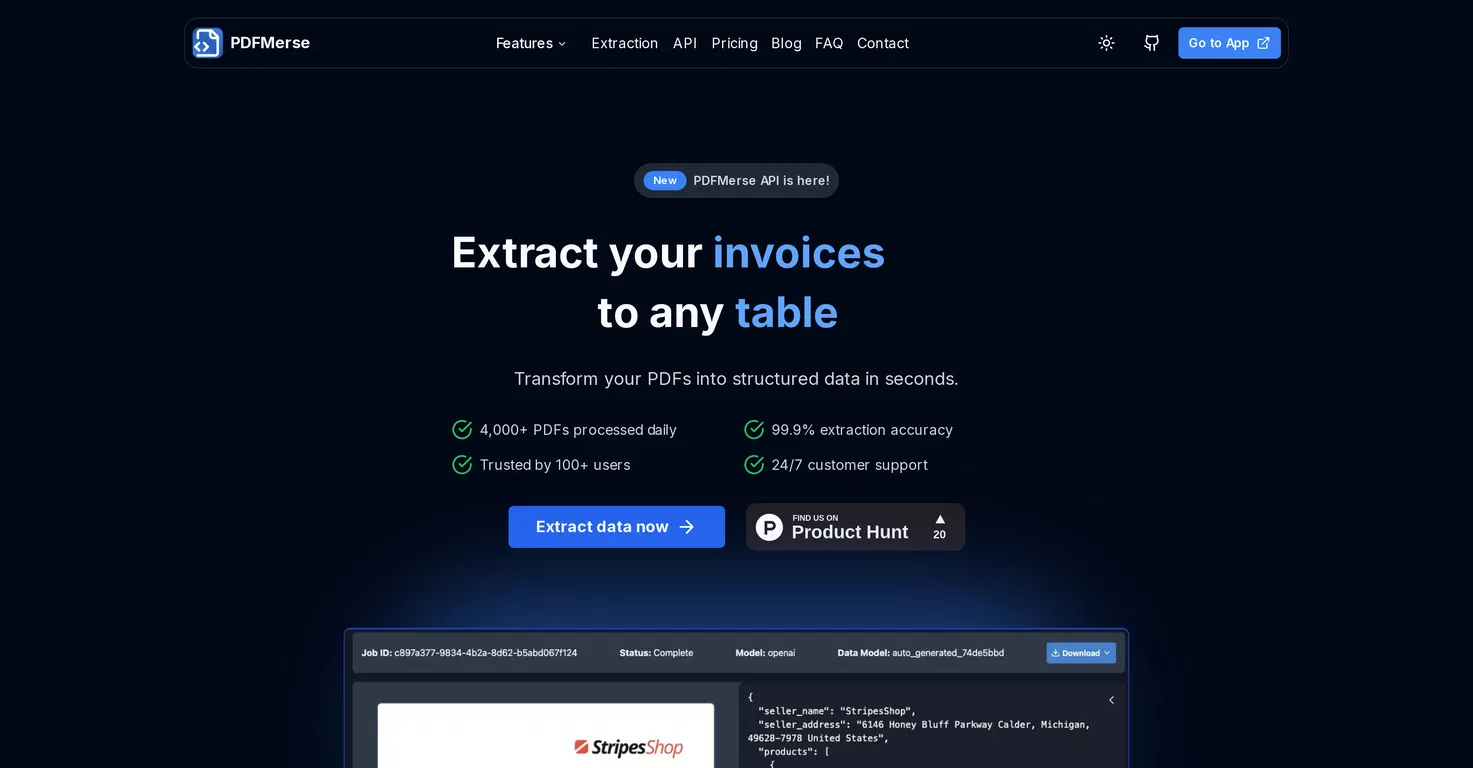
PDFMerse - это инструмент для извлечения данных с помощью искусственного интеллекта, предназначенный для извлечения данных из PDF-файлов различных форматов и преобразования их в структурированные данные. Этот инструмент революционизирует работу с данными в документах, преобразуя статичные PDF-файлы в динамичную информацию, пригодную для использования.
PDFMerse способен извлекать данные из различных типов PDF, включая счета-фактуры, юридические документы и медицинские карты. Примечательно, что он поддерживает извлечение как печатных, так и рукописных текстов в PDF, что повышает применимость инструмента в различных контекстах.
В PDFMerse встроены процессы проверки, которые позволяют поддерживать точность и целостность извлеченных данных, сводя к минимуму ошибки и несоответствия.
Пользователи могут просто описать, что они хотят извлечь, а модель данных, созданная искусственным интеллектом, сделает извлечение легким. Кроме того, инструмент поддерживает многоязычные документы, что расширяет возможности обработки глобальных данных.
Для упрощения интеграции PDFMerse предоставляет API, позволяющий извлекать данные из PDF-файлов с помощью простых HTTP-запросов. Кроме того, он обеспечивает получение выходных данных в гарантированной структуре, готовой к немедленному использованию в различных системах.
Инструмент поддерживает ряд выходных форматов, таких как CSV, JSON и Excel, чтобы удовлетворить различные потребности пользователей. Наконец, PDFMerse учитывает качество данных - он оптимизирован для скорости и эффективности, обеспечивая быстрые процессы извлечения.
Отзывы